
说到磁盘阵列这个名词大家应该不生疏,可有的小白问了磁盘阵列到底是什么东西?它有什么作用?不同的阵列之间有什么区别,这里我给大家细细道来。
有些人说磁盘阵列没什么用,数据不安全,这东西没什么意义,我想大声告诉他们大错特错,磁盘阵列的诞生恰恰就是为了数据的安全性!有些小白只知道有磁盘阵列这么个东西,但并不清楚磁盘阵列究竟是什么。为了给大家讲的清楚我就从磁盘阵列的工作原理来给大家详细的了解这个磁盘阵列。
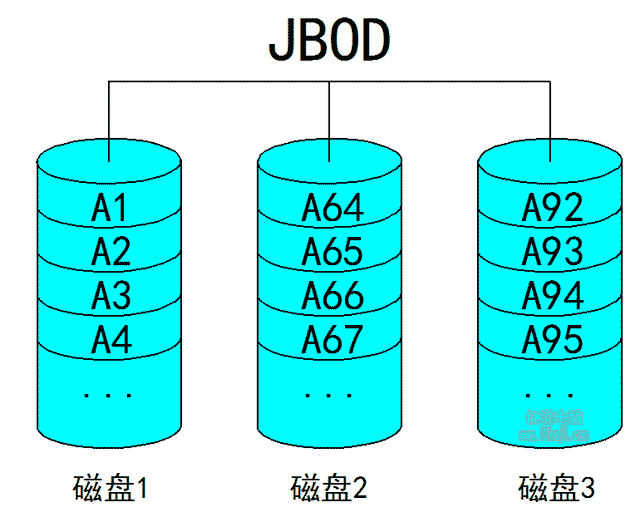
一、什么是JBOD
假设我们有多块磁盘如果我不组建磁盘阵列的话磁盘与磁盘之间是没有任何关系的,我们把文件放进磁盘A里那么跟磁盘B一点关系没有,同样的把文件放进磁盘B里它跟磁盘A也是没有什么关系的,两块磁盘是完全独立存在的,这种传统的没有任何联系的磁盘关系用英文来讲就是Just a bunch of disk,简称JBOD结构(意思是说只是一堆磁盘)。这种结构有很大的弊端,我们调取磁盘A里的数据时只是磁盘A在工作而磁盘B是空间的,调取磁盘B里的数据时只是磁盘B在工作而磁盘A是空闲的;除非我们同时获取两块磁盘的数据,不然总有一块磁盘是空闲的,这无形当中浪费了部分磁盘性能,所以为了让多块磁盘协调工作一块运转发挥它的全部性能就有了磁盘阵列这个东西。
二、磁盘阵列是什么
磁盘阵列在电脑当中我们通常称之为Raid,给多块磁盘组建Raid后我们电脑内就只会看到一个Raid的阵列盘,它的子磁盘我们是看不到的,我们就跟使用普通磁盘一样去使用这个由多块磁盘组合起来的Raid磁盘,Raid有很多的等级,目前行业公认的Raid等级为0-7,不同的Raid等级之间并没有优劣之分,它们仅仅是不同功能的阵列,只是在我们实际使用的时候需要根据不同的情况和不同的需求去灵活的决定用哪个等级的Raid,下面给大家讲解一个不同等级的Raid之间的区别、工作原理和优劣。

三、磁盘阵列有几种
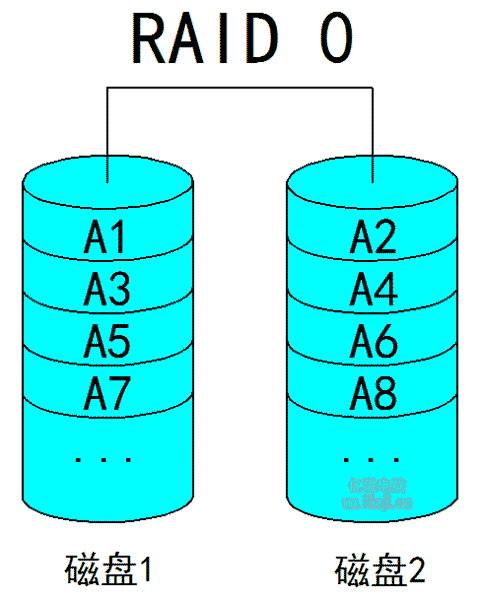
(一)Raid0:
它的工作原理类似于内存的双通道,它至少要用两块磁盘,工作原理就是将一个完整的数据拆分后分别放到两块磁盘中,写入时两块磁盘同时写入,读取时两块磁盘同时读取,和内存双通道一个道理,带宽翻倍速度翻倍的效果,比之更强的地方在于我有多少块磁盘就是可以翻多少倍的性能,不像内存那样有IMC的限制,甚至可以把南桥芯片的带宽跑到上限。但这里翻倍的速度只是连续读写的速度,Raid是无法提高随机读写性能的,因为随机读写主要考验的是硬盘的寻道和寻址能力,所以我们组建了Raid仍然改变不了硬盘随机读写性能低下的问题。硬盘还是要花大量的时间去寻道和寻址,所以组Raid随机读写性能的提高相对于单块磁盘来说提升的幅度是微弱的,也有可能是某一块磁盘拖了后腿导致木桶短板效应,以至于组Raid0后反而随机读写性能居然会弱于单块磁盘的现象,Raid0是所有阵列里速度最快的同样也是最不安全的,因为我们的数据被拆分到了多块磁盘当中,比如我们组了6块磁盘的Raid0,数据就会被拆分成6块分散在6个磁盘中,万一其中一块磁盘出了故障我们只有其他5块磁盘的数据是无法正常读取的,这就导致了整个数据全部报废,由此可见Raid0的优缺点都很极端,加的磁盘越多速度就是越快,同样的磁盘越多数据就越危险。
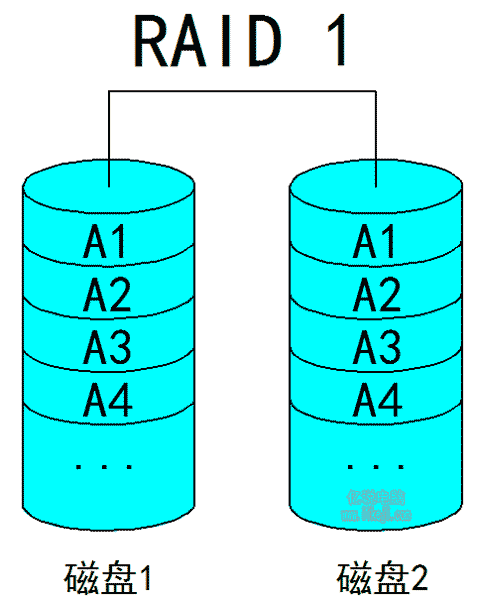
(二)Raid1:
又被叫做镜像,他也至少需要2块磁盘才能实现,其工作原理是把一份完整的数据复制到其它的磁盘当中,假设我们把2块磁盘组成Raid1,在往这个Raid1里存放数据时2块磁盘内部都会存入完全一模一样的数据,所以说Raid1就是我们平时说的自动备份。当然我们也可以手动的去复制手动备份,但手动操作是需要时间的,而我们组建好了Raid1后,就可以实现全自动实时备份了,而且组建完了Raid1以后我们在系统里只会看见1块磁盘的,这种阵列和Raid0一样也是一种极端,是所有阵列当中最安全的,但是相应的空间利用率和速度是最低的。因为,如有2块磁盘组成了Raid1,我们在系统内只能看到1块容量的磁盘,同样速度也是1块磁盘的速度。
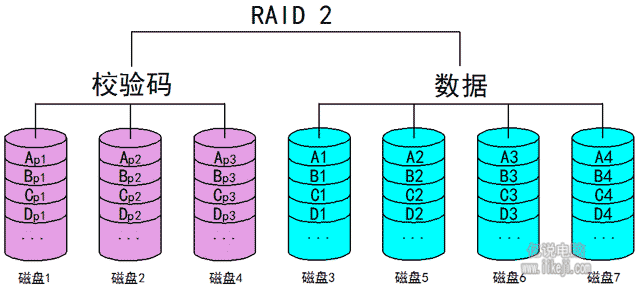
(三)Raid2:
一种利用海明码校验的一种阵列,其主要目的是在Raid0的基础上增加了数据纠错能力,注意这里是纠错而非容灾。Raid2其数据的第2的n次方为校验文件,如1、2、4、8、16、32位就是用来纠错的校验码,其他的位置才是原始数据。假设我们有一个四位编码的数据需要存储,那就需要7块磁盘,其1、2、4存放校验码,只有3、5、6、7是存放数据的。如果有一个八位编码的数据,需要存储那么1、2、4、8是校验码,而3、5、6、7、9、10、11、12是存储数据的。所以我们发现Raid2当中编码数据位数越少磁盘利用率就越低。由于一次写入数据可以往多块磁盘写入所以他具有和Raid0比较相似的并发性能,但是由于写入还需要计算校验码,读取时也需要读取校验码用于纠错,所以实际上其性能开销还是比较大的,因此使用Raid2的人还是很少的。
(四)Raid3:
它的实现至少需要3块磁盘,既然Raid0不安全,只要坏其中一块磁盘所有数据全部报废,那我们就想办法让他有一定的容灾能力。假设我用3块磁盘组了Raid0,然后我们再增加一块磁盘做为第4块,这里面存放着前面3块磁盘的恢复码,当前面3块磁盘任意一个磁盘出现故障的时候,靠着剩下2个磁盘的数据再加上恢复码我们就可以恢复丢失磁盘的数据了,而恢复码的磁盘要是损坏了也不是会影响到前面3个磁盘,所以说Raid3相对于Raid0来说容灾能力从0块增加到了1块,由于前面3块磁盘和Raid0一样,只是多了1块校验码磁盘,和Raid2海明码那种一下一堆纠错码不同,恢复码的性能还是消耗比较少的,所以Raid3的性能非常接近Raid0。

(五)Raid4:
和Raid3很像,也是在Raid0的基础上增加一块恢复码磁盘,假设Raid3和Raid4都是3个数据盘+1个恢复盘,这时我有一个文件它被分成了3组,这3组数据需要分别存储到磁盘内。Raid3就是第一组拆分加上第一组恢复码,写入;第二组拆分以后加上第二组恢复恢复码,写入;第三组拆分以后加上第三组恢复码,写入。而Raid4则是1、2、3组直接准备好,然后把1、2、3组的数据整体准备一个恢复码,再把三组数据和整体的恢复码写入进去。他们的区别是Raid3是将一个数据块拆分分别存储,校验码也是针对拆分的这一部分去进行计算的;而Raid4是直接按区块去进行存储,校验码是针对几个块一块进行计算,其容灾能力也是一块磁盘。
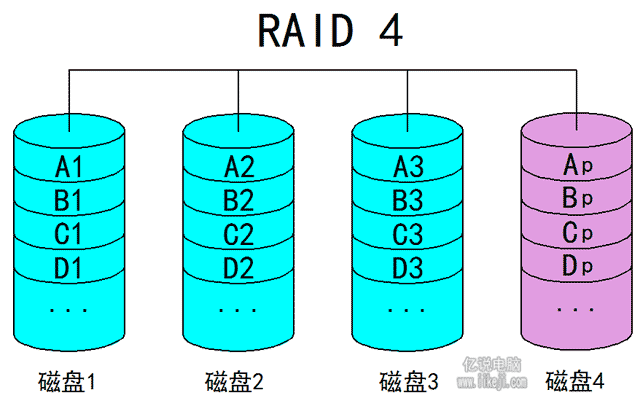
(六)Raid5:
因为Raid4也有自己的问题,3块磁盘对应1块恢复盘,如果我增加到了5块磁盘他还只是一块恢复盘,再增加到10块他也是一块恢复盘,无论多少块磁盘他都只有一块恢复盘。当我们有很多数据磁盘但只有一块恢复盘的话这个恢复盘的性能可能会制约整个阵列的性能,恢复盘的恢复数据块没有写完下次写入是无法进行的,所以我们把原本要存入恢复盘恢复码直接拆分开,每块磁盘中都分别存储一部分恢复码,这样恢复码的写入操作就会被拆分由4块磁盘共同完成。假设磁盘3故障无法读取,数据B是完整数据的,B1、B2、B3都在,不需要恢复,A1+A2+Ap可以恢复A3,C1+C3+Cp可以恢复C2,D1+D3+Dp可以恢复D2。所以Raid5一方面可以做到Raid0相似的性能,还增加了一块磁盘的容灾能力,更解决了Raid4恢复码磁盘的瓶颈,就目前来讲民用层面Raid5是使用最多的一种磁盘阵列,常见于各种私有NAS服务器里。

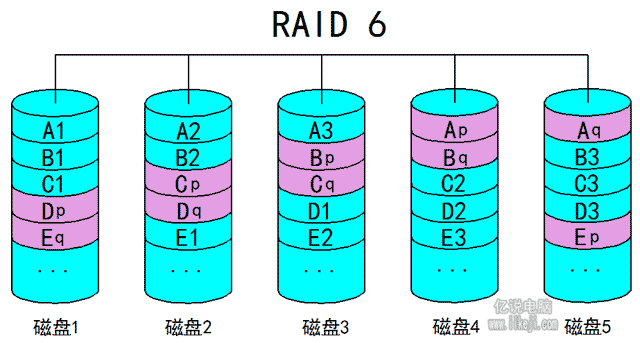
(七)Raid6:
Raid3、Radi4、Radi5都只能容灾一块磁盘的故障还是不安全,万一运气有点背同时坏掉了两块磁盘,为了解决这个问题于是有了Raid6。Raid6的恢复码相对于Raid5从1组变成了2组,这个时候如果坏了两块磁盘我们的数据还是依旧能找回的,这就让Raid6有了2块磁盘的容灾能力。
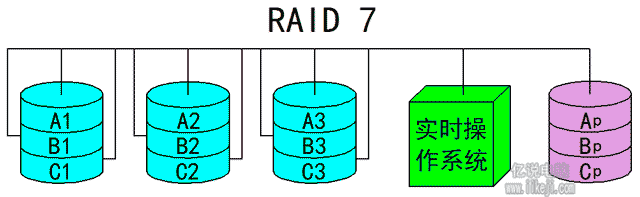
(八)Raid7:
是一种全新的Raid,它比其他几种Raid更为先进,它自身带有智能化的实时操作系统和存储管理的软件工具,可以独立于主机运行而不占用系统资源。理论上讲Raid7是性能最高也最安全的Raid架构,它的组建方式就跟Raid0-Raid6极大不同,Raid7对所有的磁盘读取写入均是同步进行的,可以分别控制每块磁盘从而提高了系统的并行性,系统访问数据的速度更快。因为每个磁盘都带有一个高速缓冲存储器,如果系统一旦断电,这个缓冲存储器里的数据会他问丢失,所以必须配备UPS一起工作,因为价格昂贵所以使用Raid7的并不多。
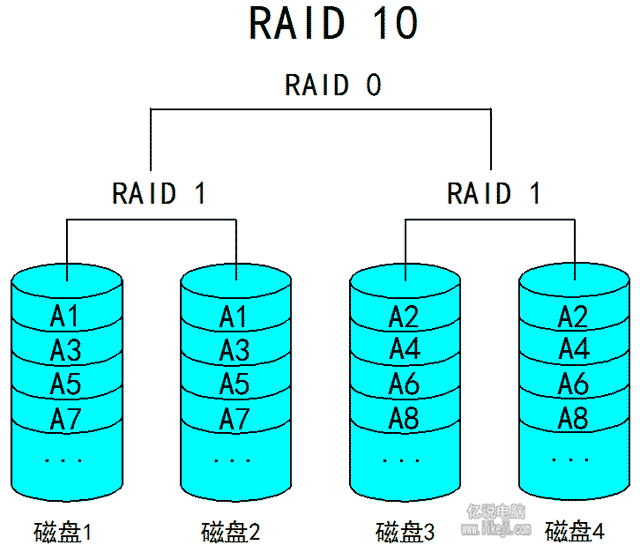
(九)Raid10:
基本上我们能接触到的大部分基础的Raid就这些,Raid除了基础的单个存在之外还可以嵌套存在。比如我们先用两个磁盘组成Raid1,用另外两个磁盘再组一个Raid1,最后把这两个Raid1组成一个Raid0,这个就是Raid10。
(十)Raid50:
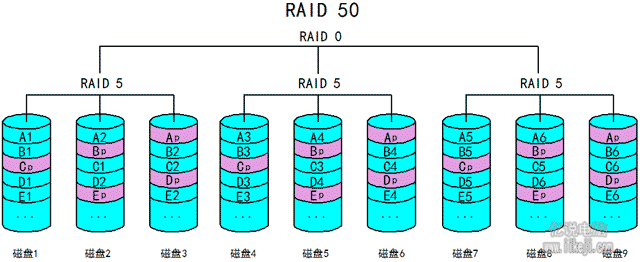
我们还可以用9块磁盘,每3块磁盘组成一个Raid5,然后再把这三个Raid5组成一个Raid0,这个就是Raid50。
四、总结
单纯从使用率来讲Raid0、Raid1、Raid5、Raid6、Raid10、Raid50用的比较多,剩下几种用的较少。但是并不是说用的少就是不好,无论用哪种Raid,如何去做嵌套组合,不同的Raid之间各有优劣,没必要非要争论出谁好谁坏,大家如果需要组建磁盘阵列的话,要灵活的根据自己的需求的实际情况下兼顾安全性与速度在实现性能提升的同时,不要因为容灾能力的低下导致数据丢失就可以了。

 版权声明
版权声明